What Is Speaker Diarization? (How It Works With Real-Life Examples)
Discover what speaker diarization is and how it separates voices in an audio file for clearer, more accurate transcription.

Our remote, digitally-driven culture is busier than ever before. As a result, the need and demand for recording and transcribing phone calls, online meetings, video conferences, doctor visits, and more are higher than ever before.
However, the scenarios mentioned above often involve a number of speakers. And in the world of audio transcription, this requires a level of technology, known as speaker diarization to enable this process and provide accurate data and quality audio recording content to end-users.
In this article, we will explain what speaker diarization is, how it works, the steps involved, and which businesses and sectors benefit most from speaker diarization in our ever-increasing digital world.
Try Rev Transcription Services
What is Speaker Diarization?
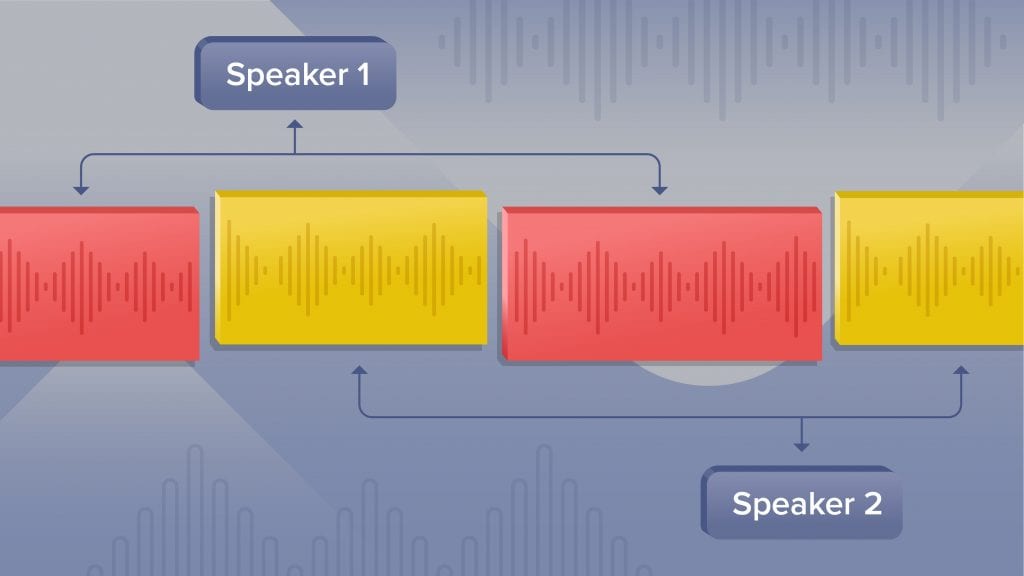
Speaker diarization is the technical process of splitting up an audio recording stream that often includes a number of speakers into homogeneous segments. These segments are associated with each individual speaker. In short, this is what the “behind the scenes” process looks like when transcribing an audio recording file.
For example, every time you opt to record a meeting from Zoom or another video conferencing application, the “speaker diarization” process takes place behind the scenes. Although speaker diarization might seem like a straightforward task, the technological model behind it is quite complex. In fact, state-of-the-art technology giants such as Rev, IBM, and Google are continuously working, building, and testing various speaker diarization system models to reduce diarization error rates and improve the overall accuracy of audio content.
See How Rev Beats Google, IBM, Amazon, and Microsoft in Accuracy
How Does a Speaker Diarization System Work?
So, this begs the question: How do automatic speech transcription systems make speaker diarization happen? As we explained above, speaker diarization transcription involves chopping up an audio recording file into shorter, single-speaker segments and embedding the segments of speech into a space that represents each individual speaker’s unique characteristics. Then, those segments are clustered and prepared for labeling. When we think of speaker diarization systems, they are broken down into “subsystems”, or smaller systems, which include the following:
- Step 1: Speech Detection: This step involves using technology to separate speech from background noise from the audio recording.
- Step 2: Speech Segmentation: This step involves pulling out small segments of an audio file. Typically there is a segment for each speaker, and approximately one second long.
- Step 3: Embedding Extraction: This step involves putting all the embedded speech segments created and collected in step two, and then creating a neural network for those segments. These embeddings can then be translated into other data formats and sources, such as text, images, documents, and so on. These different data types can then be used by a deep learning framework.
- Step 4: Clustering: After creating embeddings of the segments, as we saw in step three, the next step involves clustering those embeddings.
- Step 5: Labeling Clusters: After creating the clusters, those clusters are then labeled, typically by the number of speakers.
- Step 6: Transcription: Finally, we reach the transcription step. Once clusters are created and labeled appropriately, the audio can then be segmented into individual clips for each speaker. Those clips are then sent through a Speech-to-Text application or a speech recognition system that spits out the transcription.
Learn About Rev’s Speech-to-text API
What Are the Common Speaker Diarization Use Cases?
Businesses, practices, and firms spanning across the world use audio transcription every day for various reasons. Everything from medical and legal practices to call centers can realize the benefits of transcribing meetings and conversations.
Who uses speaker diarization and how? Speaker Diarization plays a role in many important scenarios. Many different types of businesses and professional roles rely on audio transcription. Here are some examples of common speaker diarization use cases:
- News and broadcast – recording news broadcasts for record-keeping purposes and video captioning
- Marketing – recording meetings and interviews for content creation purposes, or even call centers
- Legal – recording conversations between partners, or transcribe conversations to use as evidence
- Health care and medical services – recording medical conversations, such as between a doctor and patient or caregiver
- Software development – integrating chatbots and home assistants, such as Alexa, Google Home, and Siri into existing technology
Try Rev Transcription Services
A Real-Life Example of a Speaker Diarization
For example, let’s say a call center needed to improve the level of service provided to customers or to assist new customer service representatives with training. The call center would likely record phone calls and conversations with customers to help troubleshoot product-related issues, questions, or intake feedback on a product or service.
By transcribing those conversations, customer service supervisors can then use those audio files to train new reps or to improve the scripts or processes that reps use while interacting with customers, ultimately improving the overall customer experience.
Learn About Rev’s Speech-to-text API
Why Speaker Diarization is Valuable for Software Developers
As mentioned above, the worlds of IT and software development are among the most common use cases for speaker diarization. A simple Google search will bring up a number of articles, videos, how-to guides, and links to GitHub repositories all related to speaker diarization systems and models. We even spoke about this topic at the 2020 Interspeech convention.
Not only is it important for software developers to understand the ins and outs of speaker diarization systems and models for various development projects, but it can also help developers do their jobs. For example, developers can find API documentation in Rev’s resources.
All in all, calls, conversations, and meetings were first recorded and then later transcribed and analyzed after they have ended. However, as Google Brain and IBM continue to improve technology and speaker diarization models, it is now possible to leverage speaker diarization capabilities while meetings and calls are in progress, and access that data immediately.





